[NodeJS] JavaScript模块化
JavaScript诞生于1995年,一开始只是用于编写简单的脚本。
随着前端开发任务越来越复杂,JavaScript代码也越来越复杂,全局变量冲突、依赖管理混乱等问题变得十分突出,模块化成为一个必不可少的功能。
模块化发展史与方案对比
YUI 与 JQuery
2006年,雅虎开源了组件库YUI Library,使用类似于Java的命名空间的方式来管理模块:
YUI.util.module.doSomthing();
同年,JQuery发布,使用IIFE和闭包的方法创建私有作用域,避免全局变量污染,这种管理模块的方法流行了一段时间。
(function(root) {
// 模块内部变量和函数
var data = 'Module Data';
function getData() {
return data;
}
// 将模块接口挂载到全局对象上
root.myModule = {
getData: getData
};
})(window);
// 使用模块
console.log(myModule.getData()); // 输出: Module Data
当一个模块依赖于其它模块时:(ModuleB依赖于ModuleA和ModuleC)
(function(root, moduleA, moduleC) {
// 模块B代码
})(window, window.moduleA, window.moduleC);
这种方法有以下缺点:
- 模块挂载到了全局对象上,仍然可能存在冲突;
- 缺乏标准化,不同程序员对这种方案的实现可能不同;
- 依赖管理困难,当依赖模块量比较大时,手动传递参数容易出错。
ServerJS, CommonJS 和 Node.js
2009年1月,Mozilla 的工程师制定了一套JavaScript模块化的标准规范,取名为ServerJS,规范版本为Modules/0.1。
同年4月,ServerJS更名为CommonJS。
ServerJS最初用于服务端的JS模块化,用于辅助自动化测试工作。
在Node.js出现之前也有运行于服务端的JS,叫做Netscape Enterprise Server,它并不像Node.js,后者拥有访问操作系统文件系统,以及网络I/O等能力;而前者更像是早期的php,只是用于在服务端填充模板。更详细的介绍可以看👉Server-side JavaScript a decade before Node.js with Netscape LiveWire - DEV Community
下面这段代码摘自链接里的文章。<!-- Welcome to mid-90s HTML. Tags are SCREAMED, because everybody is very excited about THE INTERNET. --> <HTML> <HEAD> <TITLE>My awesome web app</TITLE> </HEAD> <BODY> <H1> <SERVER> /* This tag and its content will be processed on the server side, and replaced by whatever is passed to `write()` before being sent to the client. */ if(client.firstname != null) { write("Hello " + client.firstname + " !") } else { write("What is your name?") } </SERVER> </H1> <FORM METHOD="post" ACTION="app.html"> <P> <LABEL FOR="firstname">Your name</LABEL> <INPUT TYPE="text" NAME="firstname"/> </P> <P> <INPUT TYPE="submit" VALUE="Send"/> </P> </FORM> </BODY> </HTML>
同年8月,Node.js闪亮登场,但是还没有包管理器,外部依赖需要手动下载到项目文件夹中。
而包管理器的设计则需要考虑到使用什么模块化方案。Node.js的作者最终选择了同年刚提出的CommonJS作为npm的模块化方案,此时的CommonJS已经采用了Modules/1.0版本的标准规范:Modules/1.0 - CommonJS Spec Wiki
需要注意到此时的CommonJS模块化方案是针对运行在服务端的Node.js准备的,浏览器的JS出于以下原因并不能使用CommonJS:
- 同步加载模块:CommonJS使用同步的
require函数加载依赖模块,但是在浏览器环境中,网络请求加载模块文件是异步操作,无法同步执行; - 缺乏模块依赖管理:Node.js可以直接从本地文件系统或
node_modules文件夹加载模块,而浏览器无法自动处理模块的查找和加载; - 没有内置模块加载器:Node.js有内置的模块加载器,可以处理模块的解析、加载和缓存,但是浏览器没有类似的内置机制。
社区意识到为了可以在浏览器环境中使用CommonJS,必须制订新的标准规范,但是这个时候社区人员的思路出现了分歧,开始出现了不同的流派,也是从这个时候开始,出现了很多不同的模块化方案。
方向1:browserify
社区的其中一种思路是在打包代码的时候将CommonJS的模块语法转换成浏览器可以运行的代码。
相关的规范是 Modules/Transport规范,用于规定模块如何转译。
这个方向的著名产物是 Browserify。
方向2:AMD
这种思路是:由于CommonJS的require函数是同步加载模块的,没办法在浏览器环境应用,那么我们就异步地加载模块!
AMD是 Async Module Definition的简称,即异步模块定义。
James Burke在2009年9月开发了RequireJS这个模块加载器,可以异步地加载依赖。
这个方向产生了AMD标准规范:Modules/AsynchronousDefinition - CommonJS Spec Wiki
除了使用require引入依赖,还需要一个新的全局函数:define来注册依赖。
使用方法大致如下:
// module1.js
define(function() {
return {
data: 'Module 1 Data',
getData: function() {
return this.data;
}
};
});
// main.js
require(['module1'], function(module1) {
console.log(module1.getData()); // 输出: Module 1 Data
});
方向3:CMD
2011年4月,阿里巴巴的玉伯借鉴了CommonJS、AMD等模块化方案后,写出了SeaJS,在此基础上,提出了 Common Module Definition 简称CMD规范。
CMD规范的主要内容和AMD规范差不多,主要差别是CMD保留了CommonJS中最重要的延迟加载和就近声明特性。
延迟加载:
CMD 模块依赖是延迟加载的,只有在需要时才会加载依赖的模块。而 AMD 在定义模块的时候就需要加载依赖的模块了。
就近声明:
CMD在
define的回调函数中使用require函数声明依赖,而AMD中模块的依赖是在函数参数列表中显式声明的。
AMD示例:
define(['dep1', 'dep2'], function(dep1, dep2) { dep1.doSomething(); dep2.doSomething(); });CMD示例:
define(function(require, exports, module) { // 依赖在使用时才加载 var dep1 = require('./dep1'); var dep2 = require('./dep2'); exports.foo = function() { dep1.doSomething(); dep2.doSomething(); }; });
尝试统一:UMD
2014年9月,UMD被提出(Universal Module Definition),本质上不是模块化方案,只是将CommonJS和AMD进行结合。
通过检查全局作用域下是否存在exports、define方法以及全局对象上是否定义了依赖,来决定采用哪一种方法加载模块。
官方方案:ES6
到了2016年,ES6标准发布,引入了import和export两个关键字,提供了 ES Module 模块化方案。
ESM可以在编译时进行静态解析和优化,并且在后续版本中支持了动态导入(异步)。
时间线图

总结
| 模块方案 | 特点 | 优点 | 缺点 |
|---|---|---|---|
| IIFE + 闭包 | IIFE 结合闭包,实现模块化 | 简单直接,不依赖特定标准或工具 | 依赖管理复杂,易产生全局变量冲突,代码维护性和可读性较差 |
| CommonJS | 用于服务器端,同步加载 | 简单直观,广泛支持 | 不适合浏览器,需要工具转换 |
| AMD | 设计用于浏览器,异步加载 | 提高性能,依赖并行加载 | 语法复杂,代码冗长 |
| CMD | 类似 AMD,更灵活,支持延迟加载 | 灵活性高,依赖就近声明和延迟加载 | 使用较少,需要工具支持 |
| UMD | 兼容 CommonJS 和 AMD,通用模块定义 | 兼容性强,可在不同环境中使用 | 代码复杂,处理环境差异 |
| ESM | ES6 标准模块系统,静态分析 | 原生支持,静态分析,语法简洁 | 无? |
目前主流的方案是CommonJS和ESM,前者是因为历史原因,使用范围广,至今仍有许多代码使用CommonJS;而后者是官方给出的方案,简洁高效。
现在有许多转译工具例如:babel、typescript等等,可以将CommonJS转换成浏览器可以执行的形式,因此在前端项目中使用哪一种方案已经不是特别重要了。
Node.js 中的 CommonJS
在Node.js中每个文件都被看做一个模块,内部成员不会污染全局作用域,可以使用require函数引入其它模块,也可以使用module.exports导出。
模块类型
- Node.js核心模块:
fs,http,net等等; - 开发者模块:本地的文件;
- 第三方模块:通常是使用 npm 安装到
node_modules文件夹下的模块。
Node.js只会将.js,.json和.node文件视为模块,其它文件格式需要额外安装其它依赖进行转换,比如.ts。
require执行过程
解析文件路径 Resolve
require作为一个函数,传入一个字符串,首先要解析这个字符串代表哪一个模块。
这个解析的过程是调用了require.resolve()函数。
解析过程如下:
- 尝试查询该名称的
Node.js核心模块; - 如果以
./或者../开头,那么尝试解析URL,加载开发者模块(即查询文件); - 如果找不到 2. 的文件,那么尝试将字符串视为文件夹,查找文件夹内部的
index.js; - 如果还没找到,则去
node_modules文件夹内部查找指定模块并加载; - 如果还没找到,则抛出异常。
对于同名但不同格式的文件,匹配顺序是:js > json > node。
对于node_modules里的第三方模块(文件夹),是先去查找package.json里的main字段配置的入口文件,如果没有package.json文件或者没有配置main字段,则找文件夹内部的index。
其实还有很多细节这里忽略了,可以去官网看详细的匹配规则伪代码(很长):Modules: CommonJS modules | Node.js v22.4.1 Documentation (nodejs.org)
包装 Wrapping
经过上一个步骤我们已经查找到了模块对应的文件。
众所周知,代码文件都是文本文件,可以将代码读出得到一个字符串。
在这一步,模块的代码会被包装成一个函数,因此可以访问特殊对象(注入)。
(function(exports, require, module, __filename, __dirname){
// ... Module Code
})();
好处:模块的顶层代码不会泄露。
我们可以写一个简单的小案例来测试这个包装步骤:
// module.js
console.log(arguments);
// ========================================
// index.js
require('./module');
我们在index.js中引入module.js这个模块,而在module.js中,我们只做一件很简单的事情,那就是直接输出arguments对象。
执行node index.js,得到以下结果:

这五个对象分别就是exports,require,module,__filename和__dirname。
这个文件目前没有导出内容,所以可以看到第一个对象,和第三个对象module.exports是空对象。
接下来我们尝试导出点内容:
// module.js
exports.msg = 'msg from exports'
module.exports = {
msg: 'msg from module.exports'
}
console.log(arguments);
//==============================================
// index.js
const foo = require('./module');
console.log('index.js receive: ' + foo.msg);

在模块加载的时候,exports默认指向module.exports,也就是说我们要导出内容的时候,既可以通过exports,也可以通过module.exports。最终require返回的是module.exports。
通常在这个环节如果发生了意想不到的情况,大部分问题都是由赋值操作导致的。
exports如果被重新赋值,那么就和module.exports不是同一个引用了。
exports和module.exports的使用注意事项
| 特性 | module.exports | exports |
|---|---|---|
| 初始化 | 默认为一个空对象 {},可以被赋值为任何其他对象或值。 | 在模块加载时,默认与 module.exports 相同,可以通过赋值语句修改其引用。 |
| 赋值方式 | 直接赋值为需要导出的对象或值,可以是任何有效的 JavaScript 对象或函数。 | 通过 exports 的属性进行赋值,例如 exports.foo = ...。 |
| 重新赋值影响 | 若直接赋值新对象给 module.exports,会覆盖原有的导出对象。 | 若重新赋值新对象给 exports,只是修改了 exports 的引用,不会影响 module.exports。 |
| 适用场景 | 适合导出单个对象、函数或类。 | 适合在导出多个方法或属性时的简便语法。 |
| 注意事项 | 赋值给 module.exports 必须在模块加载时立即完成,不能在回调中完成赋值操作。 | 赋值给 exports 只是修改了 exports 变量的引用,而不会改变 module.exports 的引用,因此需要注意不要混淆或误用。 |
require对象
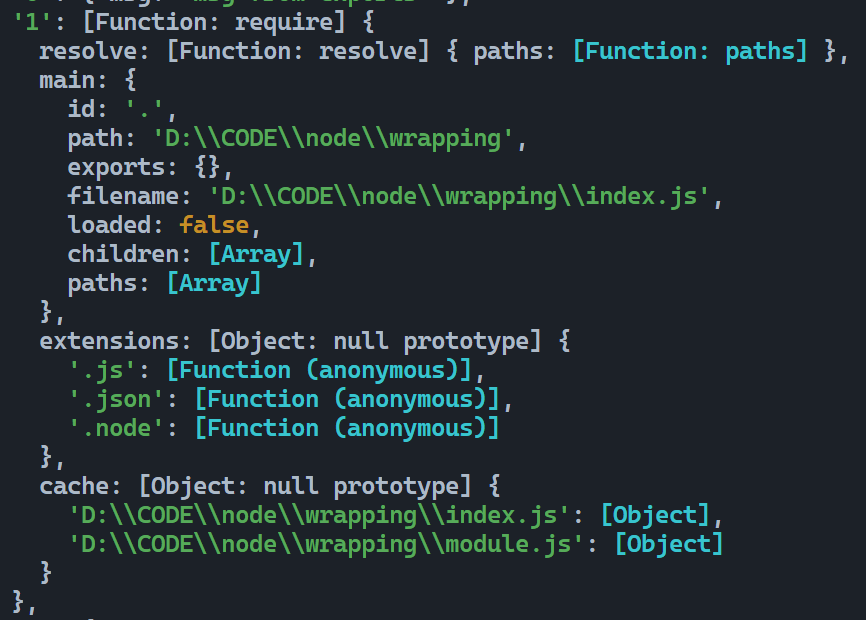
require是一个函数,当然我们都知道在JS中函数也是对象,require携带了一些很重要的属性:
-
resolve一个函数,require就是使用这个函数来将模块字符串解析为文件的具体路径的; -
main:我们知道每一个.js文件既可以被视为模块,又可以被视为主程序使用node指令启动,那么被node xxx.js执行的这个xxx.js的相关信息,就被记录到了main这个对象里,在这个案例里是index.js; -
extensions:以前用来将非js模块加载到Node.js中,已废弃,不要使用,否则可能导致bug或者性能下降; -
cache:模块的缓存记录,这里有个细节,当前模块还没有执行完成,但是已经存在一条缓存记录了,只不过当前的缓存对象可能不是最终结果(取决于console.log和module.exports的执行顺序),这个现象在下文的循环依赖问题会重点讨论。注意:缓存的
key是文件路径,而不是传给require的那个字符串,因此每次调用require引入已缓存的模块仍需要走一次resolve环节获得文件的路径。
执行 Execution
由Node.js运行时执行模块代码。
返回 Exports
require函数返回值是module.exports。
缓存 Cache
对于一个模块来说,包装和执行过程只会被执行一次,然后会被缓存。
后续对相同模块的require只会走一个解析文件路径的环节,然后就返回缓存。
循环依赖问题 Cycles
如图,模块a和模块b相互依赖,为了避免无穷循环,Node.js使用其缓存机制来处理这种问题。
官方文档案例:
a.js:
console.log('a starting');
exports.done = false;
const b = require('./b.js');
console.log('in a, b.done = %j', b.done);
exports.done = true;
console.log('a done'); COPY
b.js:
console.log('b starting');
exports.done = false;
const a = require('./a.js');
console.log('in b, a.done = %j', a.done);
exports.done = true;
console.log('b done'); COPY
main.js:
console.log('main starting');
const a = require('./a.js');
const b = require('./b.js');
console.log('in main, a.done = %j, b.done = %j', a.done, b.done); COPY
输出顺序:
main starting
a starting
b starting
in b, a.done = false
b done
in a, b.done = true
a done
in main, a.done = true, b.done = true
解析:
- 当
main.js执行require('./a.js')的时候,就已经创建一个Module对象并添加到缓存里了,只不过此时a的Module对象的exports还是空的; - 接下来执行
a.js的模块代码,exports.done赋值为false; - 执行到
require('./b.js'),发现没有相应的缓存,创建b的Module对象并添加到缓存,此时b的exports还是空对象; - 执行
b.js的模块代码,exports.done赋值为false; - 执行到
require('./a.js'),发现有缓存,直接返回模块a的module.exports对象,此时的done是false; - 注意,此时是直接返回模块a的
module.exports对象,没有去重新执行a.js的代码,因此避免了循环。 - 后续就是
b.js完成了模块代码执行,a.js完成剩余代码执行,main.js完成剩余代码执行,程序结束。
参考文章
[1] 《编程时间简史系列》JavaScript 模块化的历史进程 - 编程时间简史 - SegmentFault 思否
[2] Modules: CommonJS modules | Node.js v22.4.1 Documentation (nodejs.org)
[3] javascript - 深入Node.js的模块加载机制,手写require函数 - 进击的大前端 - SegmentFault 思否