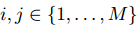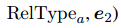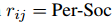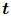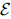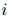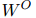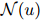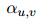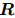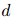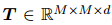为了解决传统的关系抽取(RE)方法只能识别两个实体之间的关系,而忽略了同一上下文中多个关系之间的相互依赖性,即关系的关系(relation of relations,RoR)的问题,本文提出了一种新的RE范式,它将所有关系的预测作为一个整体进行优化。本文设计了一种数据驱动的方法,利用图神经网络和关系矩阵Transformer自动学习RoR,无需人工规则。在两个公开的数据集ACE05和SemEval 2018任务7.2上,本文的模型分别比最先进的方法提高了+1.12%和+2.55%,达到了显著的改进效果。
1 Introduction
概述:
图1中的句子涉及到七个实体。在广泛使用的ACE 05数据集(Walker et al., 2006)中,有99.76%的数据实例涉及到两个以上的实体,而且每个文本中平均存在9.21个关系。
传统方法:
采用了一种简化的设置,即只对每两个实体之间的关系进行分类(Zeng et al., 2014; Luan et al., 2018; Li and Ji, 2014; Gormley et al., 2015; Miwa and Bansal, 2016)。这意味着对于图1中有7个实体的句子,大多数以前的方法需要执行49个独立的关系分类任务(如果考虑自反关系)。由于现有的方法需要对输入的实体进行显式标注,因此无法减少这个数量的分类任务。例如,要预测实体对(obstetricians, California)之间的关系,输入需要转换为“...<e1> obstetricians <\e1> in <e2> California <\e2> will pay $60,000 in Los Angeles ...”。
传统方法的问题:
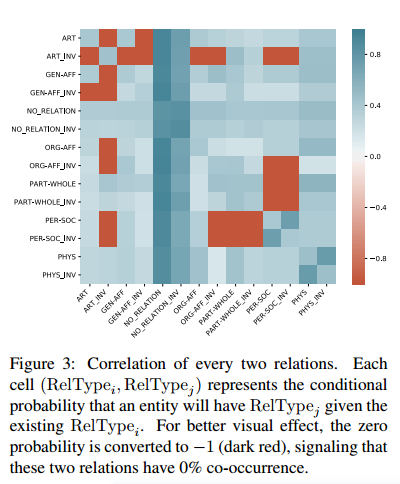
它不仅效率低下,而且忽略了同一上下文中多个关系之间的相互依赖性。例如,在图1中的49个关系中,如果已经知道了关系(Miami, is part of, south Florida),其中“is part of”是定义在两个对象上的关系,那么Miami就不太可能与其他任何人际关系有关,比如“is the father of...”。
为了捕捉RoR,本文提出了一种新的关系抽取(RE)范式,它将同一文本中所有关系的预测作为一个整体来处理。本文的工作与(Wang et al., 2019)不同,后者仍然将每个实体对的关系视为独立的分类任务,但以牺牲准确性为代价节省了计算能力,通过一次编码所有实体。相反,本文新提出的范式不是关于计算成本和准确性之间的权衡,而是通过捕捉RoR来提高性能。
2 New formulation of RE
传统的任务定义:
把每个文本序列和其中的两个实体之间的关系作为一个独立的分类问题来处理的。即:
给定一个文本序列,以及 中的两个实体提及 和 ,还有一个预定义的关系类型集合 ,任务是预测 和 之间属于哪种关系类型。这样的 RE 问题可以归结为一个经典的句子分类任务。
在准备阶段,首先为每个实体生成嵌入。利用预训练的BERT模型(Devlin et al., 2019)处理文本,并通过对BERT最后一层的每个词的隐藏状态取平均,得到每个实体的表示。本文的框架可以灵活地采用其他获取预训练嵌入的方法,例如(Yang et al., 2019; Liu et al., 2019)。接着,将两个相关实体的嵌入拼接起来,并通过一个前馈层,得到每个关系的初始嵌入。
图神经网络(GNN)具有强大的建模节点间交互的能力,这与双向关系推理(biRoR)相对应,但它在捕捉更复杂的多重关系推理(multiRoR)方面并不那么强大。例如,如果一个实体同时具有Org-Aff和Phys两种关系,那么它就不能具有Art关系。但是GNN结构并不一定能够捕捉涉及嵌套条件的这种复杂的multiRoR。因此,需要另一个模块来对关系矩阵进行建模,它考虑了所有关系之间的动态,以便捕捉multiRoR。本文提出了一个简单而有效的模块,即关系矩阵Transformer。由于关系矩阵中的每个关系都需要关注所有其他关系,本文定制了基于Transformer的编码器架构来构建关系矩阵Transformer,它允许所有元素之间进行广泛的相互注意力(Vaswani et al., 2017)。将Transformer中的位置编码定制为两部分:行编码和列编码,每一部分都是一个从位置索引到维向量空间的可学习映射。关系矩阵Transformer将位置编码,即行和列嵌入的和,加到4.1节中得到的关系的初始表示上。接着,关系矩阵Transformer学习所有关系之间的动态,并通过一个变换后的矩阵输出所有关系的新特征,从而捕捉multiRoR。最后,将GNN和关系矩阵Transformer学习到的关系嵌入相加,然后将它们输入到最终的分类层,以获得每个关系的类型。